
Architecture of a Kubernetes cluster
Let's learn the architecture of a Kubernetes cluster together

We will talk here about the architecture of Kubernetes.

So we know that Kubernetes is an orchestration tool that allows you to orchestrate your applications on a set of nodes.
What is a node?
When we talk about a node in Kubernetes, we talk about a physical or virtual machine where our containerized applications will be running.
A kubernetes cluster is a set of nodes that work together, to allow you to manage and to deploy your applications and to scale up or down depending on the traffic and on your needs.
Worker nodes
The nodes on which our applications are running, are called worker nodes. So worker nodes are meant for hosting our applications running inside containers.
Master node
In addition to the worker nodes, there is always a node that is different from the worker nodes, and it’s known as the master node or the control plane.
The master node is not dedicated for running our applications. the master node is responsible for managing the entire Kubernetes cluster, including scheduling our applications, checking the health state of the other nodes of the cluster, and checking the health state of the pods deployed on these worker nodes.
You can deploy applications on the master node, but this is not recommended, as it can interfere with its critical functions and responsibilities.
So The master node works as the leader in the entire Kubernetes cluster. and it has a different architecture and a different role compared to the other nodes of the kubernetes cluster.
Let’s deep dive into the architecture of Kubernetes, and see the differences between the architecture of the master node and the architecture of a worker node.
Master node architecture
The master node has a set of components that enable him to make global decisions about the cluster, as well as detecting and responding to cluster events.
These components are:
The Kube-apiserver
The Kube-scheduler
The controller manager
The ETCD
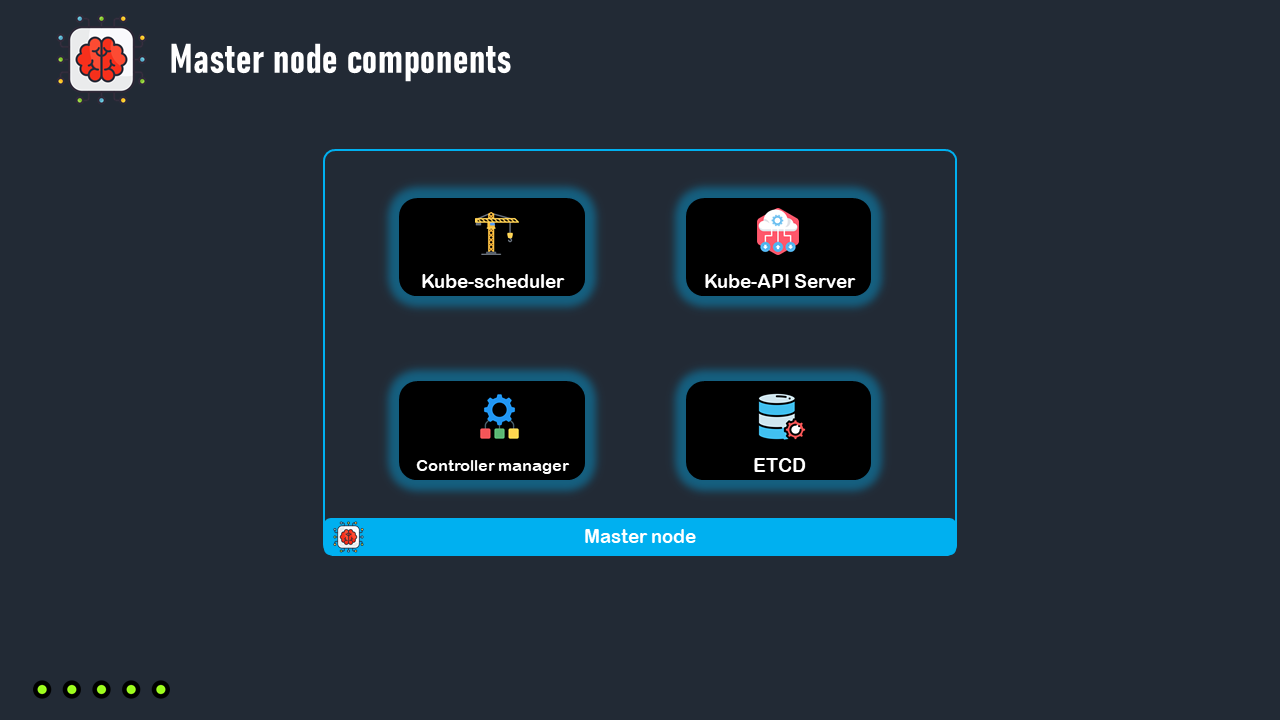
1. Kube-apiserver
First of all, we have the Kube-api server. The Kube-api server exposes the Kubernetes api. For example when deploying a pod to kubernetes , we talk to the Kube-apiserver throw a Kubernetes client like the kubectl command line tool or the kubernetes dashboard, then the Kube-api server will talk to the other components of the control plane, and after making a decision, the Kube-api server will to talk to a node to create the pod and and it will continuously talk to the worker nodes to check if the pods are running as expected.
So in Kubernetes, all the communication between the different components goes throw the Kube-api server.
2. Kube-scheduler
Next, we have the Kube-scheduler.
The Kube-scheduler is another component of the master node, and it watches for the newly created pods with no assigned node, and selects a node for them to run on.
So the decision on which node a pod can run is always made by the Kube-scheduler by examining the resource requirements and the constraints of the pod, and selecting a node that matches these requirements and that satisfies these constraints.
3. Controller manager
We have also the controller manager that runs a set of controller processes.
What you have to know about a controller in Kubernetes, is that the role of a controller is to watch the state of something in the Kubernetes cluster, and it makes requests or changes where needed to move the current state closer to the desired state.
There are many different types of controllers, including the node controller which is responsible for noticing and responding when a node goes down, and many other controllers like the job controller, the service account controller and more.
2. ETCD
Finally we have the ETCD, which is a high-available key-value data store, where the cluster data, including data about nodes, pods and any object in Kubernetes is stored.
So that’s the architecture of the master node.
Worker node architecture
We will move now to the architecture of a worker node. Each worker node has 3 components:
A container runtime
The Kube-proxy
The Kubelet
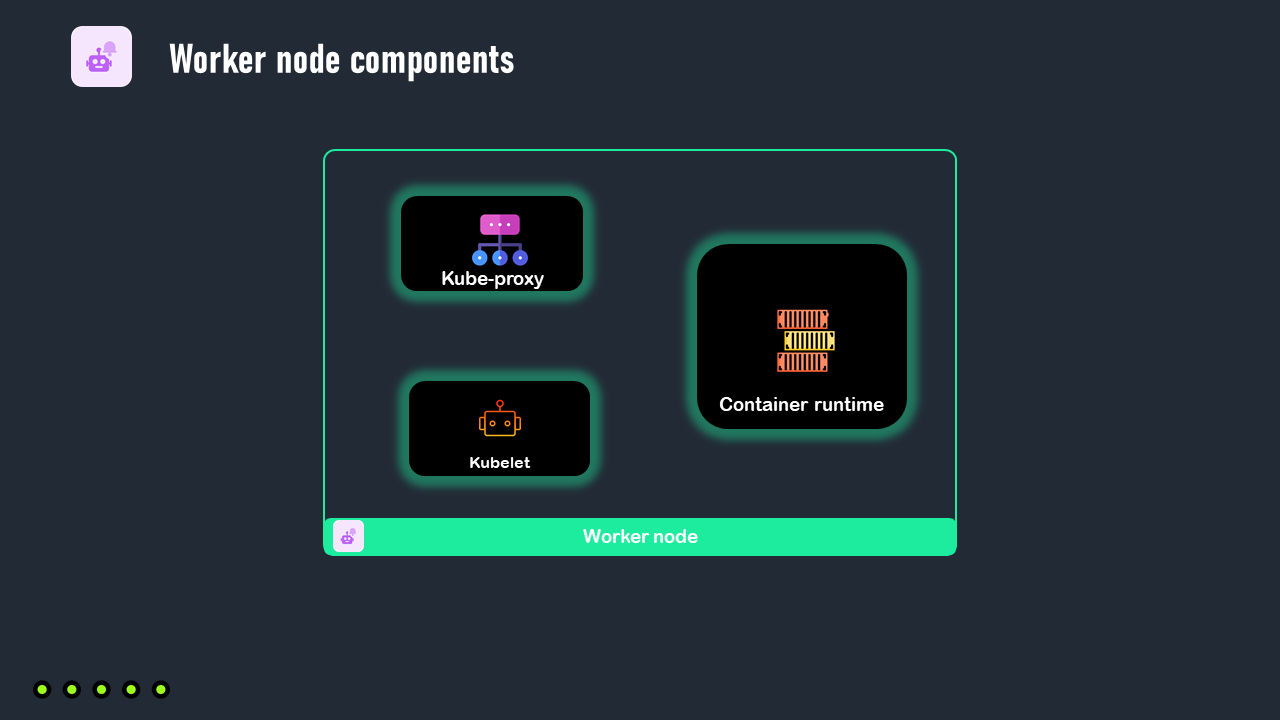
1. Container runtime
Because in Kubernetes our applications run inside containers, a container runtime must be available on each worker node, which is the software that enables the execution of containers.
Kubernetes supports different container runtimes such as Docker, Containerd and more.
2. Kube-proxy
The Kube-proxy must also be available on each worker node. The Kube-proxy maintains a set of network rules to allow to communicate to each other and to be accessible by external users.
3. Kubelet
Finally we have the Kubelet, which is an agent that takes a set of pod configurations and make sure that these pods are running and healthy, and they are configured as they are described in the pod configurations.
So the Kubelet receives orders from the master node for creating, deleting or updating pods, and it reports back to the master node data about each worker node in the cluster and about the pods running on this node.
If you want to learn more about the architecture of Kubernetes, you can watch this video in our Youtube channel
Conclusion
So a Kuberntes cluster is a set of nodes running our containerized applications inside pods. These nodes are managed by a special node known as the master node or the control plane, and the remaining nodes are known as worker nodes, and they are meant for running our containerized applications.
Whenever we want to perform an action on the cluster, for example to create a pod, we talk to the Kube-apiserver throw a Kubernetes client like the Kubernetes dashboard or the kubectl command line tool, and the Kube-api server will talk to the other components of the master node, to decide where this pod can be deployed, and after making a decision, it sends an order to the Kubelet of the appropriate worker node to create the pod.
After making sure that this pod is up and running, the Kube-proxy will enable this pod to communicate with the remaining pods running on the cluster.
You can learn more about Kubernetes and DevOps for FREE from our Youtube channel.